

java 单机接口限流处理方案
659
2022-07-11

本文主要分析了 NGINX、Kong、APISIX、Tyk、Zuul、Gravitee 几个开源 API 网关架构及基本功能,测试了一定场景下各个 API 网关的性能,文末附有源码地址。”
正文从这里开始:
春未老,风细柳斜斜。试上超然台上望,半壕春水一城花。烟雨暗千家。
寒食后,酒醒却咨嗟。休对故人思故国,且将新火试新茶。诗酒趁年华。
苏轼·送《望江南·超然台作》
温哥华的春天来了,上面的图就是我家门口的 Marine Gaetway,我今天就在这春色中和大家探讨一下 API Gateway。
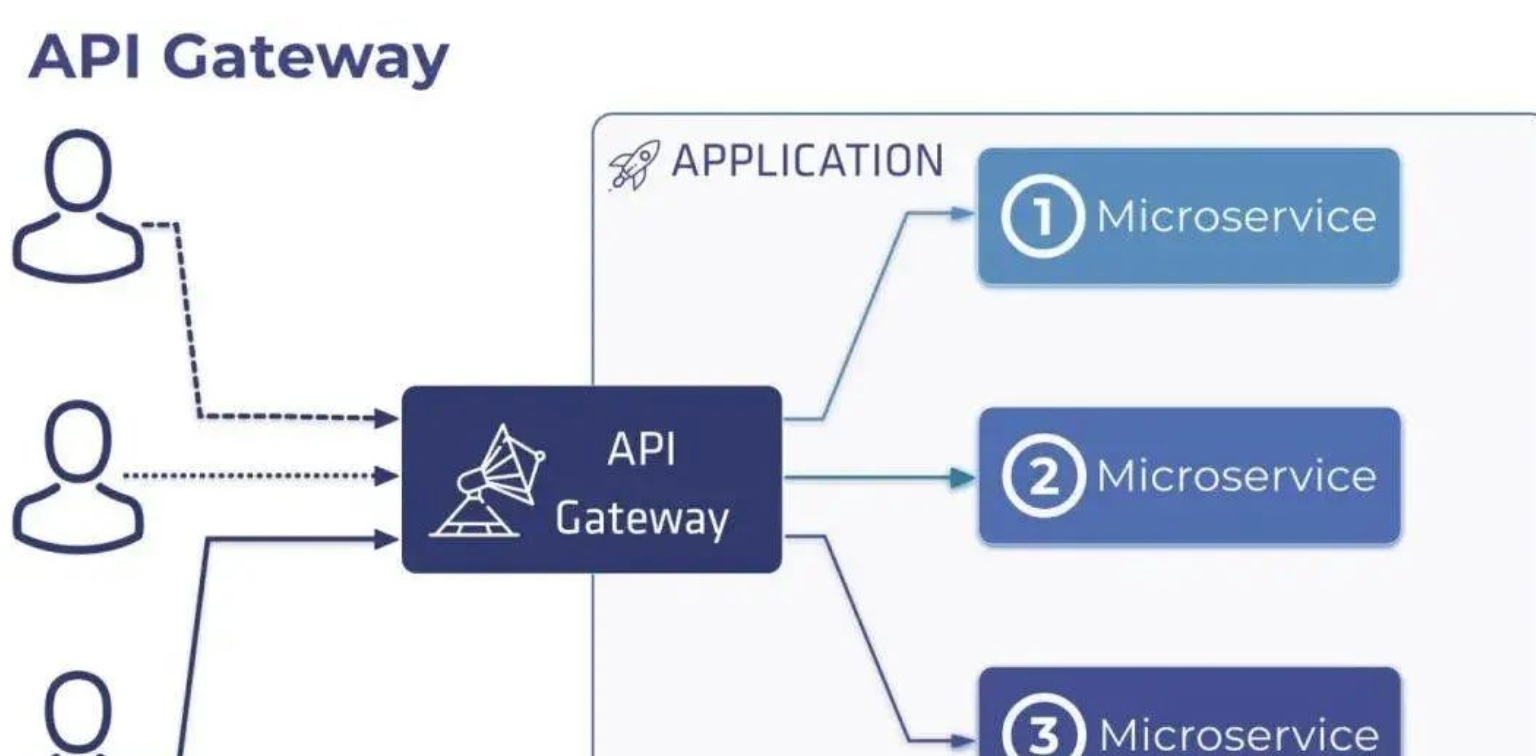
在微服务的架构下,API 网关是一个常见的架构设计模式。以下是微服务中常见的问题,需要引入 API 网关来协助解决。
微服务提供的 API 的粒度通常与客户端所需的粒度不同。微服务通常提供细粒度的 API,这意味着客户端需要与多个服务进行交互。例如,如上所述,需要产品详细信息的客户需要从众多服务中获取数据。
不同的客户端需要不同的数据。例如,产品详细信息页面桌面的桌面浏览器版本通常比移动版本更为详尽。
对于不同类型的客户端,网络性能是不同的。例如,与非移动网络相比,移动网络通常要慢得多并且具有更高的延迟。而且,当然,任何 WAN 都比 LAN 慢得多。这意味着本机移动客户端使用的网络性能与服务器端 Web 应用程序使用的 LAN 的性能差异很大。服务器端 Web 应用程序可以向后端服务发出多个请求,而不会影响用户体验,而移动客户端只能提供几个请求。
微服务实例数量及其位置(主机+端口)动态变化
服务划分会随着时间的推移而变化,应该对客户端隐藏
服务可能会使用多种协议,其中一些协议可能对网络不友好
常见的 API 网关主要提供以下的功能:
反向代理和路由 - 大多数项目采用网关的解决方案的最主要的原因。给出了访问后端 API 的所有客户端的单一入口,并隐藏内部服务部署的细节。
负载均衡 - 网关可以将单个传入的请求路由到多个后端目的地。
身份验证和授权 - 网关应该能够成功进行身份验证并仅允许可信客户端访问 API,并且还能够使用类似 RBA C等方式来授权。
IP 列表白名单/黑名单 - 允许或阻止某些 IP 地址通过。
性能分析 - 提供一种记录与 API 调用相关的使用和其他有用度量的方法。
限速和流控 - 控制 API 调用的能力。
请求变形 - 在进一步转发之前,能够在转发之前转换请求和响应(包括 Header 和 Body)。
版本控制 - 同时使用不同版本的 API 选项或可能以金丝雀发布或蓝/绿部署的形式提供慢速推出 API
断路器 - 微服务架构模式有用,以避免使用中断
多协议支持 WebSocket/GRPC
缓存 - 减少网络带宽和往返时间消耗,如果可以缓存频繁要求的数据,则可以提高性能和响应时间
API 文档 - 如果计划将 API 暴露给组织以外的开发人员,那么必须考虑使用 API 文档,例如 Swagger 或 OpenAPI。
有很多的开源软件可以提供 API 网关的支持,下面我们就看看他们各自的架构和功能。
为了对这些开源网关进行基本功能的验证,我创建了一些代码,使用 OpenAPI 生成了四个基本的 API 服务,包含 Golang,Nodejs,Python Flask 和 Java Spring。API 使用了常见的宠物商店的样例,声明如下:
openapi: "3.0.0"info: version: 1.0.0 title: Swagger Petstore license: name: MITservers: - url: http://petstore.swagger.io/v1paths: /pets: get: summary: List all pets operationId: listPets tags: - pets parameters: - name: limit in: query description: How many items to return at one time (max 100) required: false schema: type: integer format: int32 responses: '200': description: A paged array of pets headers: x-next: description: A link to the next page of responses schema: type: string content: application/json: schema: $ref: "#/components/schemas/Pets" default: description: unexpected error content: application/json: schema: $ref: "#/components/schemas/Error" post: summary: Create a pet operationId: createPets tags: - pets responses: '201': description: Null response default: description: unexpected error content: application/json: schema: $ref: "#/components/schemas/Error" /pets/{petId}: get: summary: Info for a specific pet operationId: showPetById tags: - pets parameters: - name: petId in: path required: true description: The id of the pet to retrieve schema: type: string responses: '200': description: Expected response to a valid request content: application/json: schema: $ref: "#/components/schemas/Pet" default: description: unexpected error content: application/json: schema: $ref: "#/components/schemas/Error"components: schemas: Pet: type: object required: - id - name properties: id: type: integer format: int64 name: type: string tag: type: string Pets: type: array items: $ref: "#/components/schemas/Pet" Error: type: object required: - code - message properties: code: type: integer format: int32 message: type: string
构建好的 Web 服务通过 Docker Compose 来进行容器化的部署。
version: "3.7"services: goapi: container_name: goapi image: naughtytao/goapi:0.1 ports: - "18000:8080" deploy: resources: limits: cpus: '1' memory: 256M reservations: memory: 256M nodeapi: container_name: nodeapi image: naughtytao/nodeapi:0.1 ports: - "18001:8080" deploy: resources: limits: cpus: '1' memory: 256M reservations: memory: 256M flaskapi: container_name: flaskapi image: naughtytao/flaskapi:0.1 ports: - "18002:8080" deploy: resources: limits: cpus: '1' memory: 256M reservations: memory: 256M springapi: container_name: springapi image: naughtytao/springapi:0.1 ports: - "18003:8080" deploy: resources: limits: cpus: '1' memory: 256M reservations: memory: 256M

我们在学习这些开源网关架构的同时,也会对其最基本的路由转发功能作出验证。这里用户发送的请求http://server/service_name/v1/pets会发送给 API 网关,网关通过 service name 来路由到不同的后端服务。

我们使用 K6 用 100 个并发跑 1000 次测试的结果如上图,我们看到直连的综合响应,每秒可以处理的请求数量大概是 1100+
Nginx 是异步框架的网页服务器,也可以用作反向代理、负载平衡器和 HTTP 缓存。该软件由伊戈尔·赛索耶夫创建并于 2004 年首次公开发布。2011 年成立同名公司以提供支持。2019 年 3 月 11 日,Nginx 公司被 F5 Networks 以 6.7 亿美元收购。
Nginx 有以下的特点:
由 C 编写,占用的资源和内存低,性能高。
单进程多线程,当启动 nginx 服务器,会生成一个 master 进程,master 进程会 fork 出多个 worker 进程,由 worker 线程处理客户端的请求。
支持反向代理,支持 7 层负载均衡(拓展负载均衡的好处)。
高并发,nginx 是异步非阻塞型处理请求,采用的 epollandqueue 模式
处理静态文件速度快
高度模块化,配置简单。社区活跃,各种高性能模块出品迅速。

如上图所示,Nginx 主要由 Master,Worker 和 Proxy Cache 三个部分组成。
Master 主控:NGINX 遵循主从架构。它将根据客户的要求为 Worker 分配工作。将工作分配给 Worker 后,Master 将寻找客户的下一个请求,因为它不会等待 Worker 的响应。一旦响应来自 Worker,Master 就会将响应发送给客户端
Worker 工作单元:Worker 是 NGINX 架构中的 Slave。每个工作单元可以单线程方式一次处理 1000 个以上的请求。一旦处理完成,响应将被发送到主服务器。单线程将通过在相同的内存空间而不是不同的内存空间上工作来节省 RAM 和 ROM 的大小。多线程将在不同的内存空间上工作。
Cache 缓存:Nginx 缓存用于通过从缓存而不是从服务器获取来非常快速地呈现页面。在第一个页面请求时,页面将被存储在高速缓存中。
为了实现 API 的路由转发,需要只需要对 Nginx 作出如下的配置:
server { listen 80 default_server; location /goapi { rewrite ^/goapi(.*) $1 break; proxy_pass http://goapi:8080; } location /nodeapi { rewrite ^/nodeapi(.*) $1 break; proxy_pass http://nodeapi:8080; } location /flaskapi { rewrite ^/flaskapi(.*) $1 break; proxy_pass http://flaskapi:8080; } location /springapi { rewrite ^/springapi(.*) $1 break; proxy_pass http://springapi:8080; }}
我们基于不同的服务 goapi,nodeapi,flaskapi 和 springapi,分别配置一条路由,在转发之前,需要利用 rewrite 来去掉服务名,并发送给对应的服务。
使用容器把 ngnix 和后端的四个服务部署在同一个网络下,通过网关连接路由转发的。Nginx 的部署如下:
version: "3.7"services: web: container_name: nginx image: nginx volumes: - ./templates:/etc/nginx/templates - ./conf/default.conf:/etc/nginx/conf.d/default.conf ports: - "8080:80" environment: - NGINX_HOST=localhost - NGINX_PORT=80 deploy: resources: limits: cpus: '1' memory: 256M reservations: memory: 256M
K6 通过 Nginx 网关的测试结果如下:

每秒处理的请求数量是 1093,和不通过网关转发相比非常接近。
从功能上看,Nginx 可以满足用户对于 API 网关的大部分需求,可以通过配置和插件的方式来支持不同的功能,性能非常优秀,缺点是没有管理的 UI 和管理 API,大部分的工作都需要手工配置 config 文件的方式来进行。商业版本的功能会更加完善。
Kong 是基于 NGINX 和 OpenResty 的开源 API 网关。
Kong 的总体基础结构由三个主要部分组成:NGINX 提供协议实现和工作进程管理,OpenResty 提供 Lua 集成并挂钩到 NGINX 的请求处理阶段,而 Kong 本身利用这些挂钩来路由和转换请求。数据库支持 Cassandra 或 Postgres 存储所有配置。
Kong 附带各种插件,提供访问控制,安全性,缓存和文档等功能。它还允许使用 Lua 语言编写和使用自定义插件。Kong 也可以部署为 Kubernetes Ingress 并支持 GRPC 和 WebSockets 代理。
NGINX 提供了强大的 HTTP 服务器基础结构。它处理 HTTP 请求处理,TLS 加密,请求日志记录和操作系统资源分配(例如,侦听和管理客户端连接以及产生新进程)。
NGINX 具有一个声明性配置文件,该文件位于其主机操作系统的文件系统中。虽然仅通过 NGINX 配置就可以实现某些 Kong 功能(例如,基于请求的 URL 确定上游请求路由),但修改该配置需要一定级别的操作系统访问权限,以编辑配置文件并要求 NGINX 重新加载它们,而 Kong 允许用户执行以下操作:通过 RESTful HTTP API 更新配置。Kong 的 NGINX 配置是相当基本的:除了配置标准标头,侦听端口和日志路径外,大多数配置都委托给 OpenResty。
在某些情况下,在 Kong 的旁边添加自己的 NGINX 配置非常有用,例如在 API 网关旁边提供静态网站。在这种情况下,您可以修改 Kong 使用的配置模板。
NGINX 处理的请求经过一系列阶段。NGINX 的许多功能(例如,使用 C 语言编写的模块)都提供了进入这些阶段的功能(例如,使用 gzip 压缩的功能)。虽然可以编写自己的模块,但是每次添加或更新模块时都必须重新编译 NGINX。为了简化添加新功能的过程,Kong 使用了 OpenResty。
OpenResty 是一个软件套件,捆绑了 NGINX,一组模块,LuaJIT 和一组 Lua 库。其中最主要的是 ngx_http_lua_module一个NGINX 模块,该模块嵌入 Lua 并为大多数 NGINX 请求阶段提供 Lua 等效项。这有效地允许在 Lua 中开发 NGINX 模块,同时保持高性能(LuaJIT 相当快),并且 Kong 用它来提供其核心配置管理和插件管理基础结构。
Kong 通过其插件体系结构提供了一个框架,可以挂接到上述请求阶段。从上面的示例开始,Key Auth 和 ACL 插件都控制客户端(也称为使用者)是否应该能够发出请求。每个插件都在其处理程序中定义了自己的访问函数,并且该函数针对通过给定路由或服务启用的每个插件执行 kong.access()。执行顺序由优先级值决定-如果 Key Auth 的优先级为 1003,ACL 的优先级为 950,则 Kong 将首先执行 Key Auth 的访问功能,如果它不放弃请求,则将执行 ACL,然后再通过将该 ACL 传递给上游 proxy_pass。
由于 Kong 的请求路由和处理配置是通过其 admin API 控制的,因此可以在不编辑底层 NGINX 配置的情况下即时添加和删除插件配置,因为 Kong 本质上提供了一种在 API 中注入位置块(通过 API 定义)和配置的方法。它们(通过将插件,证书等分配给这些 API)。
我们使用以下的配置部署 Kong 到容器中(省略四个微服务的部署)
version: '3.7'volumes: kong_data: {}networks: kong-net: external: falseservices: kong: image: "${KONG_DOCKER_TAG:-kong:latest}" user: "${KONG_USER:-kong}" depends_on: - db environment: KONG_ADMIN_ACCESS_LOG: /dev/stdout KONG_ADMIN_ERROR_LOG: /dev/stderr KONG_ADMIN_LISTEN: '0.0.0.0:8001' KONG_CASSANDRA_CONTACT_POINTS: db KONG_DATABASE: postgres KONG_PG_DATABASE: ${KONG_PG_DATABASE:-kong} KONG_PG_HOST: db KONG_PG_USER: ${KONG_PG_USER:-kong} KONG_PROXY_ACCESS_LOG: /dev/stdout KONG_PROXY_ERROR_LOG: /dev/stderr KONG_PG_PASSWORD_FILE: /run/secrets/kong_postgres_password secrets: - kong_postgres_password networks: - kong-net ports: - "8080:8000/tcp" - "127.0.0.1:8001:8001/tcp" - "8443:8443/tcp" - "127.0.0.1:8444:8444/tcp" healthcheck: test: ["CMD", "kong", "health"] interval: 10s timeout: 10s retries: 10 restart: on-failure deploy: restart_policy: condition: on-failure db: image: postgres:9.5 environment: POSTGRES_DB: ${KONG_PG_DATABASE:-kong} POSTGRES_USER: ${KONG_PG_USER:-kong} POSTGRES_PASSWORD_FILE: /run/secrets/kong_postgres_password secrets: - kong_postgres_password healthcheck: test: ["CMD", "pg_isready", "-U", "${KONG_PG_USER:-kong}"] interval: 30s timeout: 30s retries: 3 restart: on-failure deploy: restart_policy: condition: on-failure stdin_open: true tty: true networks: - kong-net volumes: - kong_data:/var/lib/postgresql/datasecrets: kong_postgres_password: file: ./POSTGRES_PASSWORD
数据库选择了 PostgreSQL
开源版本没有 Dashboard,我们使用 RestAPI 创建所有的网关路由:
curl -i -X POST http://localhost:8001/services \ --data name=goapi \ --data url='http://goapi:8080' curl -i -X POST http://localhost:8001/services/goapi/routes \ --data 'paths[]=/goapi' \ --data name=goapi
需要先创建一个 service,然后在该 service 下创建一条路由。
每秒请求数 705 要明显弱于 Nginx,所以所有的功能都是有成本的。
Apache APISIX 是一个动态、实时、高性能的 API 网关, 提供负载均衡、动态上游、灰度发布、服务熔断、身份认证、可观测性等丰富的流量管理功能。
APISIX 于 2019 年 4 月由中国的支流科技创建,于 6 月开源,并于同年 10 月进入Apache孵化器。支流科技对应的商业化产品的名字叫 API7 :)。APISIX 旨在处理大量请求,并具有较低的二次开发门槛。
APISIX 的主要功能和特点有:
云原生设计,轻巧且易于容器化
集成了统计和监视组件,例如 Prometheus,Apache Skywalking 和 Zipkin。
支持 gRPC,Dubbo,WebSocket,MQTT 等代理协议,以及从 HTTP 到 gRPC 的协议转码,以适应各种情况
担当 OpenID 依赖方的角色,与 Auth0,Okta 和其他身份验证提供程序的服务连接
通过在运行时动态执行用户功能来支持无服务器,从而使网关的边缘节点更加灵活
支持插件热加载
不锁定用户,支持混合云部署架构
网关节点无状态,可以灵活扩展
从这个角度来看,API 网关可以替代 Nginx 来处理南北流量,也可以扮演 Istio 控制平面和 Envoy 数据平面的角色来处理东西向流量。
APISIX 的架构如下图所示:

APISIX 包含一个数据平面,用于动态控制请求流量;一个用于存储和同步网关数据配置的控制平面,一个用于协调插件的 AI 平面,以及对请求流量的实时分析和处理。
它构建在 Nginx 反向代理服务器和键值存储 etcd 的之上,以提供轻量级的网关。它主要用 Lua 编写,Lua 是类似于 Python 的编程语言。它使用 Radix 树进行路由,并使用前缀树进行 IP 匹配。
使用 etcd 而不是关系数据库来存储配置可以使它更接近云原生,但是即使在任何服务器宕机的情况下,也可以确保整个网关系统的可用性。
所有组件都是作为插件编写的,因此其模块化设计意味着功能开发人员只需要关心自己的项目即可。
内置的插件包括流控和速度限制,身份认证,请求重写,URI 重定向,开放式跟踪和无服务器。APISIX 支持 OpenResty 和 Tengine 运行环境,并且可以在 Kubernetes 的裸机上运行。它同时支持 X86 和 ARM64。
我们同样使用 Docker Compose 来部署 APISIX。
version: "3.7"services: apisix-dashboard: image: apache/apisix-dashboard:2.4 restart: always volumes: - ./dashboard_conf/conf.yaml:/usr/local/apisix-dashboard/conf/conf.yaml ports: - "9000:9000" networks: apisix: ipv4_address: 172.18.5.18 apisix: image: apache/apisix:2.3-alpine restart: always volumes: - ./apisix_log:/usr/local/apisix/logs - ./apisix_conf/config.yaml:/usr/local/apisix/conf/config.yaml:ro depends_on: - etcd ##network_mode: host ports: - "8080:9080/tcp" - "9443:9443/tcp" networks: apisix: ipv4_address: 172.18.5.11 deploy: resources: limits: cpus: '1' memory: 256M reservations: memory: 256M etcd: image: bitnami/etcd:3.4.9 user: root restart: always volumes: - ./etcd_data:/etcd_data environment: ETCD_DATA_DIR: /etcd_data ETCD_ENABLE_V2: "true" ALLOW_NONE_AUTHENTICATION: "yes" ETCD_ADVERTISE_CLIENT_URLS: "http://0.0.0.0:2379" ETCD_LISTEN_CLIENT_URLS: "http://0.0.0.0:2379" ports: - "2379:2379/tcp" networks: apisix: ipv4_address: 172.18.5.10networks: apisix: driver: bridge ipam: config: - subnet: 172.18.0.0/16
开源的 APISIX 支持 Dashboard 的方式来管理路由,而不是像 KONG 把仪表盘功能限制在商业版本中。但是 APISIX 的仪表盘不支持对路由 URI 进行改写,所以我们只好使用 RestAPI 来创建路由。
创建一个服务的路由的命令如下:
curl --location --request PUT 'http://127.0.0.1:8080/apisix/admin/routes/1' \--header 'X-API-KEY: edd1c9f034335f136f87ad84b625c8f1' \--header 'Content-Type: text/plain' \--data-raw '{ "uri": "/goapi/*", "plugins": { "proxy-rewrite": { "regex_uri": ["^/goapi(.*)$","$1"] } }, "upstream": { "type": "roundrobin", "nodes": { "goapi:8080": 1 } }}'
使用 K6 压力测试的结果如下:

APISIX 取得了 1155 的好成绩,表现出接近不经过网关的性能,可能缓存起到了很好的效果。
Tyk 是一款基于 Golang 和 Redis 构建的开源 API 网关。它于 2014 年创建,比 AWS 的 API 网关即服务功能早。Tyk 用 Golang 编写,并使用 Golang 自己的 HTTP 服务器。
Tyk 支持不同的运行方式:云,混合(在自己的基础架构中为 GW)和本地。

Tyk 由 3 个组件组成:
网关:处理所有应用流量的代理。
仪表板:可以从中管理 Tyk,显示指标和组织 API 的界面。
Pump:负责持久保存指标数据,并将其导出到 MongoDB(内置),ElasticSearch 或 InfluxDB 等。
我们同样使用 Docker Compose 来创建 Tyk 网关来进行功能验证。
version: '3.7'services: tyk-gateway: image: tykio/tyk-gateway:v3.1.1 ports: - 8080:8080 volumes: - ./tyk.standalone.conf:/opt/tyk-gateway/tyk.conf - ./apps:/opt/tyk-gateway/apps - ./middleware:/opt/tyk-gateway/middleware - ./certs:/opt/tyk-gateway/certs environment: - TYK_GW_SECRET=foo depends_on: - tyk-redis tyk-redis: image: redis:5.0-alpine ports: - 6379:6379
Tyk 的 Dashboard 也是属于商业版本的范畴,所我们又一次需要借助 API 来创建路由,Tyk 是通过 app 的概念来创建和管理路由的,你也可以直接写 app 文件。
curl --location --request POST 'http://localhost:8080/tyk/apis/' \--header 'x-tyk-authorization: foo' \--header 'Content-Type: application/json' \--data-raw '{ "name": "GO API", "slug": "go-api", "api_id": "goapi", "org_id": "goapi", "use_keyless": true, "auth": { "auth_header_name": "Authorization" }, "definition": { "location": "header", "key": "x-api-version" }, "version_data": { "not_versioned": true, "versions": { "Default": { "name": "Default", "use_extended_paths": true } } }, "proxy": { "listen_path": "/goapi/", "target_url": "http://host.docker.internal:18000/", "strip_listen_path": true }, "active": true}'
使用 K6 压力测试的结果如下:

Tyk 的结果在 400-600 左右,性能上和 KONG 接近。
Zuul 是 Netflix 开源的基于 Java 的 API 网关组件。

Zuul 包含多个组件:
zuul-core:该库包含编译和执行过滤器的核心功能。
zuul-simple-webapp:该 Webapp 展示了一个简单的示例,说明如何使用zuul-core构建应用程序。
zuul-netflix:将其他 NetflixOSS 组件添加到 Zuul 的库-例如,使用Ribbon路由请求。
zuul-netflix-webapp:将 zuul-core 和 zuul-netflix 打包到一个易于使用的程序包中的 webapp。
Zuul 提供了灵活性和弹性,部分是通过利用其他 Netflix OSS 组件进行的:
Hystrix 用于流控。包装对始发地的呼叫,这使我们可以在发生问题时丢弃流量并确定流量的优先级。
Ribbon 是来自 Zuul 的所有出站请求的客户,它提供有关网络性能和错误的详细信息,并处理软件负载平衡以实现均匀的负载分配。
Turbine 实时汇总细粒度的指标,以便我们可以快速观察问题并做出反应。
Archaius 处理配置并提供动态更改属性的能力。
Zuul 的核心是一系列过滤器,它们能够在路由 HTTP 请求和响应期间执行一系列操作。以下是 Zuul 过滤器的主要特征:
类型:通常定义路由流程中应用过滤器的阶段(尽管它可以是任何自定义字符串)
执行顺序:在类型中应用,定义跨多个过滤器的执行顺序
准则:执行过滤器所需的条件
动作:如果符合条件,则要执行的动作
class DeviceDelayFilter extends ZuulFilter { def static Random rand = new Random() @Override String filterType() { return 'pre' } @Override int filterOrder() { return 5 } @Override boolean shouldFilter() { return RequestContext.getRequest(). getParameter("deviceType")?equals("BrokenDevice"):false } @Override Object run() { sleep(rand.nextInt(20000)) // Sleep for a random number of // seconds between [0-20] }}
Zuul 提供了一个框架来动态读取,编译和运行这些过滤器。过滤器不直接相互通信-而是通过每个请求唯一的 RequestContext 共享状态。过滤器使用 Groovy 编写。

有几种与请求的典型生命周期相对应的标准过滤器类型:
Pre 过滤器在路由到原点之前执行。示例包括请求身份验证,选择原始服务器以及记录调试信息。
Route 路由过滤器处理将请求路由到源。这是使用 Apache HttpClient 或 Netflix Ribbon 构建和发送原始 HTTP 请求的地方。
在将请求路由到源之后,将执行 Post 过滤器。示例包括将标准 HTTP 标头添加到响应,收集统计信息和指标以及将响应从源流传输到客户端。
在其他阶段之一发生错误时,将执行 Error 过滤器。
Spring Cloud 创建了一个嵌入式 Zuul 代理,以简化一个非常常见的用例的开发,在该用例中,UI 应用程序希望代理对一个或多个后端服务的调用。此功能对于用户界面代理所需的后端服务很有用,从而避免了为所有后端独立管理 CORS 和身份验证问题的需求 。
要启用它,请使用 @EnableZuulProxy 注解一个 Spring Boot 主类,这会将本地调用转发到适当的服务。
Zuul 是 Java 的一个库,他并不是一款开箱即用的 API 网关,所以需要用 Zuul 开发一个应用来对其功能进行测试。
对应的 Java 的 POM 如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>naughtytao.apigateway</groupId> <artifactId>demo</artifactId> <version>0.0.1-SNAPSHOT</version> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.4.7.RELEASE</version> <relativePath /> <!-- lookup parent from repository --> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> <!-- Dependencies --> <spring-cloud.version>Camden.SR7</spring-cloud.version> </properties> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zuul</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> <exclusions> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-log4j2</artifactId> </dependency> <!-- enable authentication if security is included --> <!-- <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> </dependency> --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- API, java.xml.bind module --> <dependency> <groupId>jakarta.xml.bind</groupId> <artifactId>jakarta.xml.bind-api</artifactId> <version>2.3.2</version> </dependency> <!-- Runtime, com.sun.xml.bind module --> <dependency> <groupId>org.glassfish.jaxb</groupId> <artifactId>jaxb-runtime</artifactId> <version>2.3.2</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-api</artifactId> <version>5.0.0-M5</version> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.3</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build></project>
主要应用代码如下:
package naughtytao.apigateway.demo;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.EnableAutoConfiguration;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration;import org.springframework.cloud.netflix.zuul.EnableZuulProxy;import org.springframework.context.annotation.ComponentScan;import org.springframework.context.annotation.Bean;import naughtytao.apigateway.demo.filters.ErrorFilter;import naughtytao.apigateway.demo.filters.PostFilter;import naughtytao.apigateway.demo.filters.PreFilter;import naughtytao.apigateway.demo.filters.RouteFilter;@SpringBootApplication@EnableAutoConfiguration(exclude = { RabbitAutoConfiguration.class })@EnableZuulProxy@ComponentScan("naughtytao.apigateway.demo")public class DemoApplication { public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); }}
Docker 构建文件如下:
FROM maven:3.6.3-openjdk-11WORKDIR /usr/src/appCOPY src ./srcCOPY pom.xml ./RUN mvn -f ./pom.xml clean package -Dmaven.wagon.http.ssl.insecure=true -Dmaven.wagon.http.ssl.allowall=true -Dmaven.wagon.http.ssl.ignore.validity.dates=true EXPOSE 8080ENTRYPOINT ["java","-jar","/usr/src/app/target/demo-0.0.1-SNAPSHOT.jar"]
路由的配置写在 application.properties 中
#Zuul routes.zuul.routes.goapi.url=http://goapi:8080zuul.routes.nodeapi.url=http://nodeapi:8080zuul.routes.flaskapi.url=http://flaskapi:8080zuul.routes.springapi.url=http://springapi:8080ribbon.eureka.enabled=falseserver.port=8080
我们同样使用 Docker Compose 运行 Zuul 的网关来进行验证:
version: '3.7'services: gateway: image: naughtytao/zuulgateway:0.1 ports: - 8080:8080 volumes: - ./config/application.properties:/usr/src/app/config/application.properties deploy: resources: limits: cpus: '1' memory: 256M reservations: memory: 256M
使用 K6 压力测试的结果如下:

在相同的配置条件下(单核,256M),Zuul 的压测结果要明显差于其它几个,只有 200 左右。

在分配更多资源的情况下,4 核 2G,Zuul 的性能提升到 600-800,所以 Zuul 对于资源的需求还是比较明显的。
另外需要提及的是,我们使用的是 Zuul1,Netflix 已经推出了 Zuul2。Zuul2 对架构做出了较大的改进。Zuul1 本质上就是一个同步 Servlet,采用多线程阻塞模型。Zuul2 的基于 Netty 实现了异步非阻塞编程模型。同步的方式,比较容易调试,但是多线程本身需要消耗 CPU 和内存资源,所以它的性能要差一些。而采用非阻塞模式的 Zuul,因为线程开销小,所支持的链接数量要更多,也更节省资源。
Gravitee 是 http://Gravitee.io 开源的,基于 Java 的,简单易用,性能高,且具成本效益的开源 API 平台,可帮助组织保护,发布和分析您的 API。

Gravitee 可以通过设计工作室和路径的两种方式来创建和管理 API

Gravity 提供网关,API 门户和 API 管理,其中网关和管理 API 部分是开源的,门户需要注册许可证来使用。
后台使用 MongoDB 作为存储,支持 ES 接入。
我们同样使用 Docker Compose 来部署整个 Gravitee 的栈。
## Copyright (C) 2015 The Gravitee team (http://gravitee.io)## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.#version: '3.7'networks: frontend: name: frontend storage: name: storagevolumes: data-elasticsearch: data-mongo:services: mongodb: image: mongo:${MONGODB_VERSION:-3.6} container_name: gio_apim_mongodb restart: always volumes: - data-mongo:/data/db - ./logs/apim-mongodb:/var/log/mongodb networks: - storage elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:${ELASTIC_VERSION:-7.7.0} container_name: gio_apim_elasticsearch restart: always volumes: - data-elasticsearch:/usr/share/elasticsearch/data environment: - http.host=0.0.0.0 - transport.host=0.0.0.0 - xpack.security.enabled=false - xpack.monitoring.enabled=false - cluster.name=elasticsearch - bootstrap.memory_lock=true - discovery.type=single-node - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ulimits: memlock: soft: -1 hard: -1 nofile: 65536 networks: - storage gateway: image: graviteeio/apim-gateway:${APIM_VERSION:-3} container_name: gio_apim_gateway restart: always ports: - "8082:8082" depends_on: - mongodb - elasticsearch volumes: - ./logs/apim-gateway:/opt/graviteeio-gateway/logs environment: - gravitee_management_mongodb_uri=mongodb://mongodb:27017/gravitee?serverSelectionTimeoutMS=5000&connectTimeoutMS=5000&socketTimeoutMS=5000 - gravitee_ratelimit_mongodb_uri=mongodb://mongodb:27017/gravitee?serverSelectionTimeoutMS=5000&connectTimeoutMS=5000&socketTimeoutMS=5000 - gravitee_reporters_elasticsearch_endpoints_0=http://elasticsearch:9200 networks: - storage - frontend deploy: resources: limits: cpus: '1' memory: 256M reservations: memory: 256M management_api: image: graviteeio/apim-management-api:${APIM_VERSION:-3} container_name: gio_apim_management_api restart: always ports: - "8083:8083" links: - mongodb - elasticsearch depends_on: - mongodb - elasticsearch volumes: - ./logs/apim-management-api:/opt/graviteeio-management-api/logs environment: - gravitee_management_mongodb_uri=mongodb://mongodb:27017/gravitee?serverSelectionTimeoutMS=5000&connectTimeoutMS=5000&socketTimeoutMS=5000 - gravitee_analytics_elasticsearch_endpoints_0=http://elasticsearch:9200 networks: - storage - frontend management_ui: image: graviteeio/apim-management-ui:${APIM_VERSION:-3} container_name: gio_apim_management_ui restart: always ports: - "8084:8080" depends_on: - management_api environment: - MGMT_API_URL=http://localhost:8083/management/organizations/DEFAULT/environments/DEFAULT/ volumes: - ./logs/apim-management-ui:/var/log/nginx networks: - frontend portal_ui: image: graviteeio/apim-portal-ui:${APIM_VERSION:-3} container_name: gio_apim_portal_ui restart: always ports: - "8085:8080" depends_on: - management_api environment: - PORTAL_API_URL=http://localhost:8083/portal/environments/DEFAULT volumes: - ./logs/apim-portal-ui:/var/log/nginx networks: - frontend
我们使用管理 UI 来创建四个对应的 API 来进行网关的路由,也可以用 API 的方式,Gravitee 是这个开源网关中,唯一管理 UI 也开源的产品。
使用 K6 压力测试的结果如下:

和同样采用 Java 的 Zuul 类似,Gravitee 的响应只能达到 200 左右,而且还出现了一些错误。我们只好再一次提高网关的资源分配到 4 核 2G。

提高资源分配后的性能来到了 500-700,稍微好于 Zuul。
本文分析了几种开源 API 网关的架构和基本功能,为大家在架构选型的时候提供一些基本的参考信息,本文做作的测试数据比较简单,场景也比较单一,不能作为实际选型的依据。
Nginx
Nginx 基于 C 开发的高性能 API 网关,拥有众多的插件,如果你的 API 管理的需求比较简单,接受手工配置路由,Nginx 是个不错的选择。
Kong
Kong 是基于 Nginx 的 API 网关,使用 OpenResty 和 Lua 扩展,后台使用 PostgreSQL,功能众多,社区的热度很高,但是性能上看比起 Nginx 有相当的损失。如果你对功能和扩展性有要求,可以考虑 Kong。
APISIX
APISIX 和 Kong 的架构类似,但是采用了云原生的设计,使用 ETCD 作为后台,性能上比起 Kong 有相当的优势,适合对性能要求高的云原生部署的场景。特别提一下,APISIX 支持 MQTT 协议,对于构建 IOT 应用非常友好。
Tyk
Tyk 使用 Golang 开发,后台使用 Redis,性能不错,如果你喜欢 Golang,可以考虑一下。要注意的是 Tyk 的开源协议是 MPL,是属于修改代码后不能闭源,对于商业化应用不是很友好。
Zuul
Zuul 是 Netflix 开源的基于 Java 的 API 网关组件,他并不是一款开箱即用的 API 网关,需要和你的 Java 应用一起构建,所有的功能都是通过集成其它组件的方式来使用,适合对于 Java 比较熟悉,用 Java 构建的应用的场景,缺点是性能其他的开源产品要差一些,同样的性能条件下,对于资源的要求会更多。
Gravitee
Gravitee 是 http://Gravitee.io 开源的基于 Java 的 API 管理平台,它能对 API 的生命周期进行管理,即使是开源版本,也有很好的 UI 支持。但是因为采用了 Java 构建,性能同样是短板,适合对于 API 管理有强烈需求的场景。
随着互联网技术的飞速发展,各类线上业务蓬勃发展,软件系统如雨后春笋般呈现在我们面前。
为了提高系统的性能和可靠性,将应用服务进行拆分微服务化。作为系统入口的 API 网关也逐渐成为了标配。
今天我们一起来看看 API 网关的设计思路,需要承载了哪些功能?以及如何选择流行的 API 网关?
什么是 API 网关
既然需要 API 网关为我所用,首先就让我们来了解一下什么是 API 网关。
什么是 API 网关
网关一词最早出现在网络设备,比如两个相互独立的局域网之间通过路由器进行通信,中间的路由被称之为网关。
任何一个应用系统如果需要被其他系统调用,就需要暴露 API,这些 API 代表着一个一个的功能点。
如果两个系统中间通信,在系统之间加上一个中介者协助 API 的调用,这个中介者就是 API 网关。
对接两个系统的 API 网关
当然,API 网关可以放在两个系统之间,同时也可以放在客户端与服务端之间。
对接客户端和服务端的 API 网关
知道了 API 网关的基本定义,再来看看为什么我们要使用它。
为何要使用 API 网关
网关作为系统的唯一入口,也就是说,进入系统的所有请求都需要经过 API 网关。
当系统外部的应用或者客户端访问系统的时候,都会遇到这样的情况:
系统要判断它们的权限
如果传输协议不一致,需要对协议进行转换
如果调用水平扩展的服务,需要做负载均衡
一旦请求流量超出系统承受的范围,需要做限流操作
针对每个请求以及回复,系统会记录响应的日志
也就是说,只要是涉及到对系统的请求,并且能够从业务中抽离出来的功能,都有可能在网关上实现。
例如:协议转换,负载均衡,请求路由,流量控制等等。后面我们会一一给大家介绍这些功能。
在了解 API 网关有哪些基本功能以后,来看看它可以服务于哪些系统或者客户端。
API 网关服务定位
API 网关拥有处理请求的能力,从定位来看分为 5 类:
①面向 WebApp,这部分的系统以网站和 H5 应用为主。通过前后端分离的设计,将大部分的业务功能都放在了后端,前面的 Web App 只展示页面的内容。
②MobileApp,这里的 Mobile 指的是 iOS 和 Android,设计思路和 WebApp 基本相同。
区别是 API 网关需要做一些移动设备管理的工作(MDM)。例如:设备的注册,激活,使用,淘汰等,全生命周期的管理。
由于移动设备的特殊性,导致了我们在考虑移动设备请求的时候,需要考虑请求,设备,使用者之间的关系。
③面向合作伙伴的 OpenAPI,通常系统会给合作伙伴提供接口。这些接口会全部开放或者部分开发,在有条件限制(时间,流量)的情况下给合作伙伴访问。因此需要更多考虑 API 网关的流量和安全以及协议转换的管理。
④企业内部可扩展 API,给企业内部的其他部门或者项目使用,也可以作为中台输出的一部分,支持其他系统。这里需要更多地考虑划分功能边界,认证和授权问题。
⑤面向 IOT 设备,会接收来自 IOT 设备的请求,特别是工业传感器等设备。这里需要考虑协议转换和数据过滤。
API 网关架构
既然谈了 API 网关的功能和定位,接下来说说它的架构:
API 网关系统架构图
API 网关拆分成为 3 个系统:
Gateway-Core(核心)
Gateway-Admin(管理)
Gateway-Monitor(监控)
Gateway-Core 核心网关,负责接收客户端请求,调度、加载和执行组件,将请求路由到上游服务端,并处理其返回的结果。
大多数的功能都在这一层完成,例如:验证,鉴权,负载均衡,协议转换,服务路由,数据缓存。如果没有其他两个子系统,它也是可以单独运行的。
Gateway-Admin 网关管理界面,可以进行 API、组件等系统基础信息的配置;例如:限流的策略,缓存配置,告警设置。
Gateway-Monitor 监控日志、生成各种运维管理报表、自动告警等;管理和监控系统主要是为核心系统服务的,起到支撑的作用。
API 网关技术原理
上面谈到了网关的架构思路,这里谈几点技术原理。平时我们在使用网关的时候,多注重其实现的功能。例如:路由,负载均衡,限流,缓存,日志,发布等等。
实际上这些功能的背后有一些原理我们可以了解,这样在应用功能的时候会更加笃定。下面是几个原理分享给大家。
协议转换
每个系统内部服务之间的调用,可以统一使用一种协议,例如:HTTP,GRPC。
假设每个系统使用的协议不同,那么系统之间的调用或者数据传输,就存在协议转换的问题了。如果解决这个问题呢?API 网关通过泛化调用的方式实现协议之间的转化。
实际上就是将不同的协议转换成“通用协议”,然后再将通用协议转化成本地系统能够识别的协议。
这一转化工作通常在 API 网关完成。通用协议用得比较多的有 JSON,当然也有使用 XML 或者自定义 JSON 文件的。
不同的协议需要转化成共同语言进行传输
链式处理
设计模式中有一种责任链模式,它将“处理请求”和“处理步骤”分开。每个处理步骤,只关心这个步骤上需要做的处理操作,处理步骤存在先后顺序。
消息从第一个“处理步骤”流入,从最后一个“处理步骤”流出,每个步骤对经过的消息进行处理,整个过程形成了一个链条。在 API 网关中也用到了类似的模式。
Zuul 网关过滤器链式处理
下面以 Zuul 为例,当消息出入网关需要经历一系列的过滤器。这些过滤器之间是有先后顺序的,并且在每个过滤器需要进行的工作也是各不一样:
PRE:前置过滤器,用来处理通用事务,比如鉴权,限流,熔断降级,缓存。并且可以通过 Custom 过滤器进行扩展。
ROUTING:路由过滤器,在这种过滤器中把用户请求发送给 Origin Server。它主要负责:协议转化和路由的工作。
POST:后置过滤器,从 Origin Server 返回的响应信息会经过它,再返回给调用者。在返回的 Response 上加入 Response Header,同时可以做 Response 的统计和日志记录。
ERROR:错误过滤器,当上面三个过滤器发生异常时,错误信息会进到这里,并对错误进行处理。
异步请求
所有的请求通过 API 网关访问应用服务,一旦吞吐量上去了,如何高效地处理这些请求?拿 Zuul 为例,Zuul1 采用:一个线程处理一个请求的方式。线程负责接受请求,然后调用应用返回结果。如果把网络请求看成一次 IO 操作的话,处理请求的线程,从接受请求,到服务返回响应,都是阻塞状态。
同时,如果多个线程都处在这种状态,会导致系统缓慢。因为每个网关能够开启的线程数量是有限的,特别是在访问的高峰期。
每个线程处理一个请求为了解决这个问题,Zuul2 启动了异步请求的机制。每个请求进入网关的时候,会被包装成一个事件,CPU 内核会维持一个监听器,不断轮询“请求事件”。一旦,发现请求事件,就会调用对应的应用。获取应用返回的信息以后,按照请求的要求把数据/文件放到指定的缓冲区,同时发送一个通知事件,告诉请求端数据已经就绪,可以从这个缓冲获取数据/文件。这个过程是异步的,请求的线程不用一直等待数据的返回。它在请求完毕以后,就直接返回了,这时它可以做其他的事情。
当请求数据被 CPU 内核获取,并且发送到指定的数据缓冲区时,请求的线程会接到“数据返回”的通知,然后就直接使用数据,不用自己去做取数据的操作。
异步请求处理,CPU 处理数据以后通知请求端实现异步处理请求有两种模式,分别是:
Reactor
Proactor
Reactor 工作原理流水图Reactor:通过 handle_events 事件循环处理请求。用户线程注册事件处理器之后,可以继续执行其他的工作(异步),而 Reactor 线程负责调用内核的 Select 函数检查 Socket 状态。当有 Socket 被激活时(获取网络数据),则通知相应的用户线程,执行 handle_event 进行数据读取、处理的工作。
Proactor 工作原理流水图
Proactor:用户线程使用 CPU 内核提供的异步 IO 发起请求,请求发起以后立即返回。CPU 内核继续执行用户请求线程代码。此时用户线程已将 AsynchronousOperation(异步处理)和 CompletionHandler(完成获取资源)注册到内核。之后操作系统开启独立的内核线程去处理 IO 操作。当请求的数据到达时,由内核负责读取 Socket(网络请求)中的数据,并写入用户指定的缓冲区中。最后内核将数据和用户线程注册的 CompletionHandler 分发给内部 Proactor,Proactor 将 IO 完成的信息通知给用户线程(一般通过调用用户线程注册的完成事件处理函数),完成异步 IO。
API 网关实现功能
说起对 API 网关的使用,我们还是对具体功能更加感兴趣。让我们一起来看看它实现了哪些功能。
负载均衡
当网关后面挂接同一应用的多个副本时,每次用户的请求都会通过网关的负载均衡算法,路由到对应的服务上面。例如:随机算法,权重算法,Hash 算法等等。如果上游服务采取微服务的架构,也可以和注册中心合作实现动态的负载均衡。
当微服务动态挂载(动态扩容)的时候,可以通过服务注册中心获取微服务的注册信息,从而实现负载均衡。
Nginx+Lua+服务注册中心实现动态负载均衡
路由选择
这个不言而喻,网关可以根据请求的 URL 地址解析,知道需要访问的服务。再通过路由表把请求路由到目标服务上去。
有时候因为网络原因,服务可能会暂时的不可用,这个时候我们希望可以再次对服务进行重试。
Zuul 作为 API 网关将请求路由到上游服务器
例如:Zuul 与 Spring Retry 合作完成路由重试。
#是否开启重试功能
zuul.retryable=true
#对当前服务的重试次数
ribbon.MaxAutoRetries=2
流量控制
限流是 API 网关常用的功能之一,当上游服务超出请求承载范围,或者服务因为某种原因无法正常使用,都会导致服务处理能力下滑。这个时候,API 网关作为“看门人”,就可以限制流入的请求,让应用服务器免受冲击。
限流实际上就是限制流入请求的数量,其算法不少,有令牌桶算法,漏桶算法,连接数限制等等。这里我们就介绍三个常用的,一般通过 Nginx+Lua 来实现。
令牌桶限流
统一鉴权
访问应用服务器的请求都需要拥有一定权限,如果说每访问一个服务都需要验证一次权限,这个对效率是很大的影响。可以把权限认证放到 API 网关来进行。目前比较常见的做法是,用户通过登录服务获取 Token,把它存放到客户端,在每次请求的时候把这个 Token 放入请求头,一起发送给服务器。API 网关要做的事情就是解析这个 Token,知道访问者是谁(鉴定),他能做什么/访问什么(权限)。说白了就是看访问者能够访问哪些 URL,这里根据权限/角色定义一个访问列表。如果要实现多个系统的 OSS(Single Sign On 单点登录),API 网关需要和 CAS(Central Authentication Service 中心鉴权服务)做连接,来确定请求者的身份和权限。
熔断降级
当应用服务出现异常,不能继续提供服务的时候,也就是说应用服务不可用了。作为 API 网关需要做出处理,把请求导入到其他服务上。或者对服务进行降级处理,例如:用兜底的服务数据返回客户端,或者提示服务暂时不可用。同时通过服务注册中心,监听存在问题的服务,一旦服务恢复,随即恢复路由请求到该服务。
例如:Zuul 中提供了 ZuulFallbackProvider 接口来实现熔断,它提供两个方法,一个指明熔断拦截的服务 getRoute,一个指定返回内容 ClientHttpResponse。
public interface ZuulFallbackProvider {
/**
* The route this fallback will be used for.
* @return The route the fallback will be used for.
*/
public String getRoute();
/**
* Provides a fallback response.
* @return The fallback response.
*/
public ClientHttpResponsefallbackResponse();
}
我们通过自定义的 Fallback 方法,并且将其指定给某个 Route 来实现该 Route 访问出问题的熔断处理。
主要继承 ZuulFallbackProvider 接口来实现,ZuulFallbackProvider 默认有两个方法,一个用来指明熔断拦截哪个服务,一个定制返回内容。
API 网关熔断降级
发布测试
在发布版本的时候会采用:金丝雀发布和蓝绿发布。作为 API 网关可以使用路由选择和流量切换来协助上述行为。这里以金丝雀发布为例,看看 API 网关如何做路由转换的。
假设将 4 个服务从 V1 更新到 V2 版本,这 4 个服务的流量请求由 1 个 API 网关管理。
那么先将一台服务与 API 网关断开,部署 V2 版本的服务,然后 API 网关再将流量导入到 V2 版本的服务上。
这里流量的导入可以是逐步进行的,一旦 V2 版本的服务趋于稳定。再如法炮制,将其他服务替换成 V2 版本。
金丝雀发布一般先发 1 台,或者一个小比例,例如 2% 的服务器,主要做流量验证用,也称为金丝雀(Canary)测试(灰度测试)。
其来历是,旷工下矿洞前,先放一只金丝雀探查是否有毒气,金丝雀发布由此得名。
金丝雀测试需要完善的监控设施配合,通过监控指标反馈,观察金丝雀的健康状况,作为后续发布或回滚的依据。
如果金丝测试通过,则把剩余的 V1 版本全部升级为 V2 版本。如果金丝雀测试失败,则直接回退金丝雀,发布失败。
缓存数据
我们可以在 API 网关缓存一些修改频率不高的数据。例如:用户信息,配置信息,通过服务定期刷新这个缓存就行了:
用户请求先访问 API 网关,如果发现有缓存信息,直接返回给用户。
如果没有发现缓存信息,回源到应用服务器获取信息。
另外,有一个缓存更新服务,定期把应用服务器中的信息更新到网关本地缓存中。
日志记录
通过 API 网关上的过滤器我们可以加入日志服务,记录请求和返回信息。同时可以建立一个管理员的界面去监控这些数据。
日志服务简图日志记录了以后,可以做很多功能扩展。我们整理了以下几点供大家参考:
报表分析:针对服务访问情况,提供可视化展示。
实时查询:了解实时关键信息,例如:吞吐量,并发数。在秒杀活动的时候,会特别关注。
异常告警:针对关键参数进行监控,对于统计结果支持阈值报警,对接阿里云通知中心、短信、钉钉进行告警。
日志投递:将日志进行归档,存放到文件库或者数据仓库中,以便后期分析。
日志记录衍生的功能
流行 API 网关对比
在介绍了 API 网关的功能以后,再来看看目前几个流行的 API 网关项目。看看他们各自的特点,并且把他们做一个简单的比较。这些网关目前都是开源的,大家可以有选择地在项目中使用。
Kong
Kong 是 Mash ape 公司的开源项目,它是一个在 Nginx 中运行的 Lua 应用程序,并且可以通过 Lua-Nginx 模块实现扩展。所以,可以通过插件集合的方式定制功能,例如:HTTP 基本认证、密钥认证、CORS(Cross-origin Resource Sharing,跨域资源共享)、TCP、UDP、日志、API 限流、请求转发以及监控,都是目前已有的插件。
由于是基于 Nginx 的,所以可以对网关进行水平扩展,来应对大批量的网络请求。
Kong 架构图Kong 主要有三个组件:
KongServer :基于 Nginx 的服务器,用来接收 API 请求。
ApacheCassandra/PostgreSQL:用来存储操作数据。
Kongdashboard:UI 管理工具。
Traefik
Traefik 架构图Traefik 是 HTTP 反向代理和负载均衡器,可以轻松部署微服务,可以与现有的组件(Docker、Swarm,Kubernetes,Marathon,Consul,Etcd)做集成。因为支持动态配置,所以它的伸缩性很好。不过它只支持 HTTP、HTTPS 和 GRPC。如果你需要 TCP 负载均衡,那么您需要选择其他方案了。
Ambassador
Ambassador 架构图Ambassador 是一个基于 Envoy Proxy 构建的,Kubernetes 原生的开源微服务网关。它在构建之初就致力于支持多个独立的团队,这些团队需要为最终用户快速发布、监控和更新服务。Ambassador 还具有 Kubernetes Ingress 和负载均衡的能力。它支持处理 Kubernetes Ingress Controller 和负载均衡等功能,可以与 Istio 无缝集成。
Zuul
Zuul 2 结构图Zuul 是 Spring Cloud 全家桶中的微服务 API 网关。所有从设备或网站来的请求都会经过 Zuul 到达后端的 Netflix 应用程序。作为一个边界性质的应用程序,Zuul 提供了动态路由、监控、弹性负载和安全功能。包括 Zuul1 和 Zuul2 两个版本。
介绍了几个开源 API 网关的基本信息以后,我们从几个维度对他们进行比较:
从开源社区活跃度来说,Kong 和 Traefik 较好;从成熟度来看,较好的是 Kong、Traefik;从架构优势的扩展性来看,Kong 有丰富的插件,Ambassador 也有插件但不多,而 Zuul 是需要自研。但 Zuul 由于与 Spring Cloud 集成,如果使用 Spring Cloud 的小伙伴可以考虑使用。
总结
API 网关是系统内外通讯的中介者。从定位上来说它服务 WebApp,MobileApp,合作伙伴 OpenAPI,企业内部可扩展 API,以及 IOT 设备。从架构设计角度来说,分为 Gateway-Core(核心)、Gateway-Admin(管理)、Gateway-Monitor(监控)三部分。API 网关需要注意的技术原理有,协议转换,链式处理以及异步请求。它的应用比较广泛,例如:负载均衡,路由选择,流量控制,统一鉴权,熔断降级,发布测试,缓存数据,日志记录等。比较流行的开源 API网关有 Kong,Traefik,Ambassador,Zuul。从使用上来说他们各有千秋,可以根据项目的情况选取。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论
暂时没有评论,来抢沙发吧~